

默认KeyValueTextInputFormat的数据输入是通过,空格来截取,区分key和value的值,这里我们通过自定义来实现通过 “,”来截取。
一,准备文件数据: 
2,自定义MyFileInputFormat类:
import java.io.IOException;
import org.apache.Hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
public class MyFileInputFormat extends FileInputFormat<Text, Text> {
@Override
public RecordReader<Text, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
context.setStatus(split.toString());
return new MyLineRecordReader(context.getConfiguration());
}
}
3,自定义MyLineRecordReader类,并修改其中的截取方法:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.LineRecordReader;
public class MyLineRecordReader extends RecordReader<Text, Text> {
public static final String KEY_VALUE_SEPERATOR = "mapreduce.input.keyvaluelinerecordreader.key.value.separator";
private final LineRecordReader lineRecordReader;
private byte separator = (byte) ',';
private Text innerValue;
private Text key;
private Text value;
public Class getKeyClass() {
return Text.class;
}
public MyLineRecordReader(Configuration conf)
throws IOException {
lineRecordReader = new LineRecordReader();
String sepStr = conf.get(KEY_VALUE_SEPERATOR, ",");
this.separator = (byte) sepStr.charAt(0);
}
public void initialize(InputSplit genericSplit, TaskAttemptContext context) throws IOException {
lineRecordReader.initialize(genericSplit, context);
}
public static int findSeparator(byte[] utf, int start, int length, byte sep) {
for (int i = start; i < (start + length); i++) {
if (utf[i] == sep) {
return i;
}
}
return -1;
}
public static void setKeyValue(Text key, Text value, byte[] line, int lineLen, int pos) {
if (pos == -1) {
key.set(line, 0, lineLen);
value.set("");
} else {
key.set(line, 0, pos);
value.set(line, pos + 1, lineLen - pos - 1);
}
}
/** Read key/value pair in a line. */
public synchronized boolean nextKeyValue() throws IOException {
byte[] line = null;
int lineLen = -1;
if (lineRecordReader.nextKeyValue()) {
innerValue = lineRecordReader.getCurrentValue();
line = innerValue.getBytes();
lineLen = innerValue.getLength();
} else {
return false;
}
if (line == null)
return false;
if (key == null) {
key = new Text();
}
if (value == null) {
value = new Text();
}
int pos = findSeparator(line, 0, lineLen, this.separator);
setKeyValue(key, value, line, lineLen, pos);
return true;
}
public Text getCurrentKey() {
return key;
}
public Text getCurrentValue() {
return value;
}
public float getProgress() throws IOException {
return lineRecordReader.getProgress();
}
public synchronized void close() throws IOException {
lineRecordReader.close();
}
}
4,测试类的书写:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Test{
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
String[] paths = new GenericOptionsParser(conf, args).getRemainingArgs();
if(paths.length < 2){
throw new RuntimeException("usage <input> <output>");
}
Job job = Job.getInstance(conf, "wordcount2");
job.setJarByClass(Test.class);
job.setInputFormatClass(MyFileInputFormat.class);
//job.setInputFormatClass(TextInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPaths(job, paths[0]);//同时写入两个文件的内容
FileOutputFormat.setOutputPath(job, new Path(paths[1] + System.currentTimeMillis()));//整合好结果后输出的位置
System.exit(job.waitForCompletion(true) ? 0 : 1);//执行job
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
5,结果: 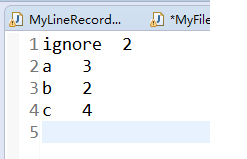
下面关于Hadoop的文章您也可能喜欢,不妨看看:
Ubuntu14.04下Hadoop2.4.1单机/伪分布式安装配置教程 http://www.linuxidc.com/Linux/2015-02/113487.htm
CentOS安装和配置Hadoop2.2.0 http://www.linuxidc.com/Linux/2014-01/94685.htm
Ubuntu 13.04上搭建Hadoop环境 http://www.linuxidc.com/Linux/2013-06/86106.htm
Ubuntu 12.10 +Hadoop 1.2.1版本集群配置 http://www.linuxidc.com/Linux/2013-09/90600.htm
Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) http://www.linuxidc.com/Linux/2013-01/77681.htm
Ubuntu下Hadoop环境的配置 http://www.linuxidc.com/Linux/2012-11/74539.htm
单机版搭建Hadoop环境图文教程详解 http://www.linuxidc.com/Linux/2012-02/53927.htm








