


这是一个发生在 2015年 的故事。中国的互联网经济进入高速发展的时期。各种互联网创业公司层出不穷,人们争先恐后地加入到这场浪潮中来。
故事的主人公小明是个有远大理想的小朋友,有一些的开发经验,更有敏锐的市场洞察力。 他发现以 uber 和 airbnb 为代表的共享经济正在变成一个热点,新加入的 “回家吃饭 “也是来势汹汹。这些公司涵盖了食、住、行等领域的共享,但市面上还没有衣服共享的公司。他又想到自己有很多闲置的运动鞋,何不开一个在垂直领域共享运动鞋的创业公司。他兴奋得一夜没睡,马上注册了一个叫 air-sneakers 的公司。召集了几个工程师朋友热火朝天地干起来了。

创业艰辛
首先他们着手设计数据模型。在数据模型中最重要的表叫 ATHLETIC_SHOES 表。这个表大概长成这样:

小明又为常用的一些品牌,材料,尺码等重要数据建了一些关联表。接着,小明又做好了 PRD 和 wireframe。 小明的工程师们选择了熟悉的 java 语言来开发。每个页面基本针对一张表的增删改查,用 iBatis 之类的 OR mapping 开发的后端和 angular 开发的前端很快就完成了。两个月后第一版上线了!
很快,小明注意到了一个问题。并不是很多人都有很多闲置的运动鞋,也不是每个人都喜欢每天穿不同的运动鞋。和公司 CFO (小明太太)商量后,他果断决定推出女鞋共享,女人的闲置鞋会多一些。
小明的工程师发现原来设计的数据模型根本不够用。女鞋可不像运动鞋那么简单,光一个单鞋就有什么高跟,低跟,平跟,粗跟,细跟,圆头,尖头,真皮,假皮等等属性,连鞋码都不一样。新的女鞋表大概是这样的.
WOMENS_SHOES

当然还有 WOMENS_PUMPS 表,WOMENS_BOOTS 表,WOMENS_SANDALS 表,等等……此处略去 10000 字
原来的代码基本上没用了,小明还被工程师打了。
新的代码花了很长时间才写出来,特别复杂,到处都是 if else 之类的判断。总算,新版本上线了。但是用户还是不买账。原来,女人也不喜欢穿别人的旧鞋,也没有那么多人喜欢把自己的鞋借给别人,过上脚气都不知道。
小明再次调整战略,开发出了一版包括所有服装共享的 app 改名为 air-wardrobe。这次新的表结构就没那么简单了,大大小小建了上百张表。

大家天天加班,苦苦干了一年。因为屡次改需求,小明又受伤住院了。
峰回路转
总算,新 app 上线为小明拉来了第一笔风投。投资方不希望小明只做服装共享,应该涵盖所有家用产品。无奈下,小明找来了一个架构师设计新的数据模型。架构师看到旧的 schema 设计抚掌大笑,指出了旧 schema 的最大问题。
传统横向 schema 的缺点:
- 在插入数据时,需要向许多张表里先后插入数据,并要保证数据的一致性。
- 当需要显示来自不同表的信息时,需要连接多张表。前端在显示产品列表时要显示的字段常常不在一张表里。经常为了显示一个字段而要多连接几张表,并做各种复杂的查询。
- 一个表的列越多,数据冗余也越多
- 不同的维度,事实和度量需要建立跟多的错综复杂的关系,并要维护这些一致性。
- 所有传统关系型数据库的缺点
新数据模型是这样设计出来的。首先是一张 PRODUCT 表。这张表包含了世界上所有产品共有的属性。如分类,新旧,价格,数量。

然后,那些为各类商品单独建的表和它们的关联表都不需要了。取代他们的是一个垂直的 schema. 首先需要的是一张表描述商品的元数据(meta data)“PROD_ATTRIBUTES”,用来存放所有产品属性的定义。
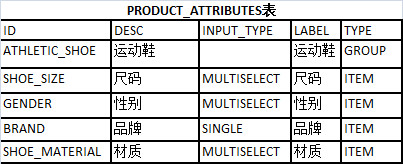
对于每一种商品,我们只需要定义他们独有的属性,不同商品可以共享一些属性,比如运动鞋和女鞋共享鞋码的属性。
对每样商品的每个属性,我们插入一条数据来保存它。这就需要一个 PROD_ATTR_VALUE 表
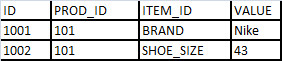
- 过去我们选择一条商品数据用这样的 SQL:Select * from athletic_shoes where id = 1001
- 现在用的 SQL 还是一样:Select * from PROD_ATTR_VALUE where PROD_ID= 1001
区别只是在显示方向上,过去是横向显示的, 现在是纵向显示的。过去是宽的,现在是窄的。
用旧 schema,通常我们会为每张表对应一个类。方便 OR mapping。用新 schema 任何商品只需要一种数据结构来表示,就是 Map,准确地说是 Multimap,因为考虑到有一对多的属性。 Multimap 数据结构和流行的 JSON 数据结构和 Http 请求的 query 是很相似的,很适合互联网应用。
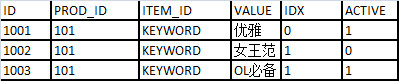
传统 schema 里,一对多的关系是通过连接表和外键实现的。比如一双鞋可能包括许多流行元素,假设旧 scheme 里为这些流行元素的关键字建了一个 SHOE_KEYWORDS 表,和 shoes 表为一对多关系。
在垂直 schema 里,只需要加一个 IDX 字段可以实现一对多关系。如下表:这个商品 101 有两个 keywords。

如果要保存每次产品更新记录便于存档呢?过去,可能需要加一个类似 shoe_edit_history 的表。每次改动时把旧数据搬到这张表里,再创建一条新数据。
在新 schema 里只要加一个 ACTIVE 字段标识最新的改动,就能达到目的。
过去对于下拉框式的输入的值,传统上我们通常会需要其他表的辅助。
比如在旧表里可能有个 HEEL_TYPE_ID 的字段,表示不同跟高。另外有一张 VALID_HEEL_TYPES 表保存所有合法的跟高。或者像小明那样用一个 enum 之类的 hard code 在代码里。
在新 schema 里,我们会用到一个 CODE_LIST 的关联表,下面这张表描述了鞋码和跟高两个 code list。非常适合在下拉框显示它们。
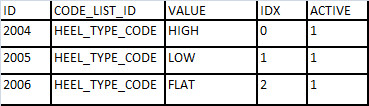
新 schema 如何把相关的信息组合在一起?只要加一个 PROD_ATTR_GROUP 表。

事实上应该为这些数据建立一个树状的层级关系:
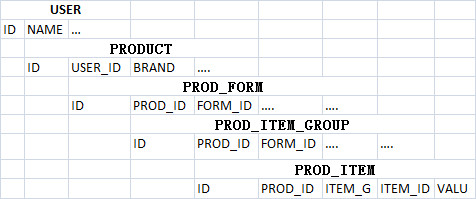
(注)PROD_ID 字段在 PROD_ITEM 表中出现是一种去范式化,为了更方便查询。
有了这样一个数据模型,录入和显示每种商品用的都是同一套代码,基本不需要为特殊产品和特殊客户改后端的代码。小明的团队做了以下分工:
- 项目经理:每开发一种新产品时,项目经理需要定义一组属性,并为这些属性分组,指定验证方式,指定 code list 等等 (产品足够多是可以开发一个工具来帮助 PM 的)。
- 前端工程师:以项目经理定义的产品属性,用工具自动生成一个录入数据的模板,一个展示数据的模板,和一个数据列表的模板。 必要的话可以针对每种产品货客户做些定制,最后把定制后的模板保存。可能需要为产品审核,订单等也生成一些模板。调用后端 API 把数据在模板理显示出来。
- 后端工程师:开发一个 RESTful API 负责录入数据,显示数据,更改数据和,产品列表。还需要一些其他 API 来管理产品,分类,批量录入,等等。
- 架构师:负责指定流程和标准,开发框架和工具,包括代码生成器。
当然这样的数据模型也是有缺点的:
- 插入数据多影响性能 - 可通过 batch 插入来改善
- 多属性的查询不方便 - 必须通过自连接(self-join)来查。
- 数据统计,挖掘不易 - 需要通过 ETL 等工具把竖表展开成宽表。
- 数据冗余大 - 此类数据通常具有实效性,可以定期存档(archive)
以上数据模型只是一个简单化例子。这类数据模型比较适合金融,电商,医药等行业。在设计这类模型时需要和传统的关系型模型间找到一个折衷方案。
故事结尾
小明的公司很快拿到了更多投资,一年后上市了。小明和太太在加勒比小岛上 live happily ever after。小明的工程师们也分到了期权,工作也很开心,再也不用为改需求大动干戈了。他们向小明道歉并得到了谅解。

- 不要怪 PM 改需求,可能是代码设计有问题。足够灵活的设计可以做到不改或少改代码。
- 要做产品化的应用,产品的种类和客户的需求常常是未知的,机械地为每个产品的每组属性添加新表和新字段是不动脑筋的设计。
- Simplicity is the ultimate sophistication。如果你的数据库里有几百张表,后端几百个服务,不值得骄傲。
- 数据模型设计不要被业务牵着鼻子走,照着前端的页面在后端做增删改查是低级的开发方式。
- 软件设计和架构是很重要的,它能帮助我们以最小的代价干最多的事。
- 代码是可以用来生成代码的,数据是可以用来描述数据的。
- 码农和工程师的区别是:码农是代码的搬运工,工程师是代码的创造者










